欢迎使用 WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!
博客
-

Mistral开源Devstral 2与Vibe CLI;智谱开源GLM-ASR-Nano语音识别模型【AI早报 12月10日】
AI 早报 2025-12-10
概览
-
Mistral AI发布Devstral 2与Vibe CLI #1 -
智谱发布GLM-ASR-Nano-2512语音识别模型 #2 -
智谱开源AutoGLM手机智能助理框架 #3 -
Linux基金会成立Agentic AI基金会 #4 -
Gemini CLI 加入候补名单可获 Gemini 3访问 #5 -
Google Stitch推出Predictive Heatmaps功能 #6 -
Augment Code发布Context Engine SDK #7 -
Qwen Code发布近期版本更新说明 #8 -
DiffSynth-Studio发布Qwen-Image-i2L模型 #9 -
Cognitive-Lab发布多语言多模态嵌入模型NetraEmbed #10 -
NousResearch开源Nomos-1模型 #11 -
One-to-All Animation发布高效角色动画模型 #12 -
inclusionAI发布TwinFlow框架 #13 -
stepfun-ai开源PaCoRe推理框架 #14 -
Cerebras发布DeepSeek-V3.2压缩模型 #15 -
Qwen团队发文介绍SAPO强化学习方法 #16 -
OpenAI发布首批认证课程 #17 -
Google测试Veo 3.1模板功能 #18 -
OpenAI新图像模型疑似现身 #19 -
Meta Avocado模型延期至2026年 #20 -
阿里成立千问C端事业群 #21 -
印度拟推AI训练版权新规 #22 -
美国战争部宣布GenAi.mil军事AI平台 #23 -
欧盟委员会调查Google涉嫌反竞争行为 #24 -
fal完成1.4亿美元D轮融资 #25
Mistral AI发布Devstral 2与Vibe CLI
#1Mistral AI 推出了新一代编程模型家族
Devstral 2和配套的命令行工具Mistral Vibe CLI,旨在提供强大的代码生成与自动化能力。Mistral AI 发布了其下一代编程模型家族
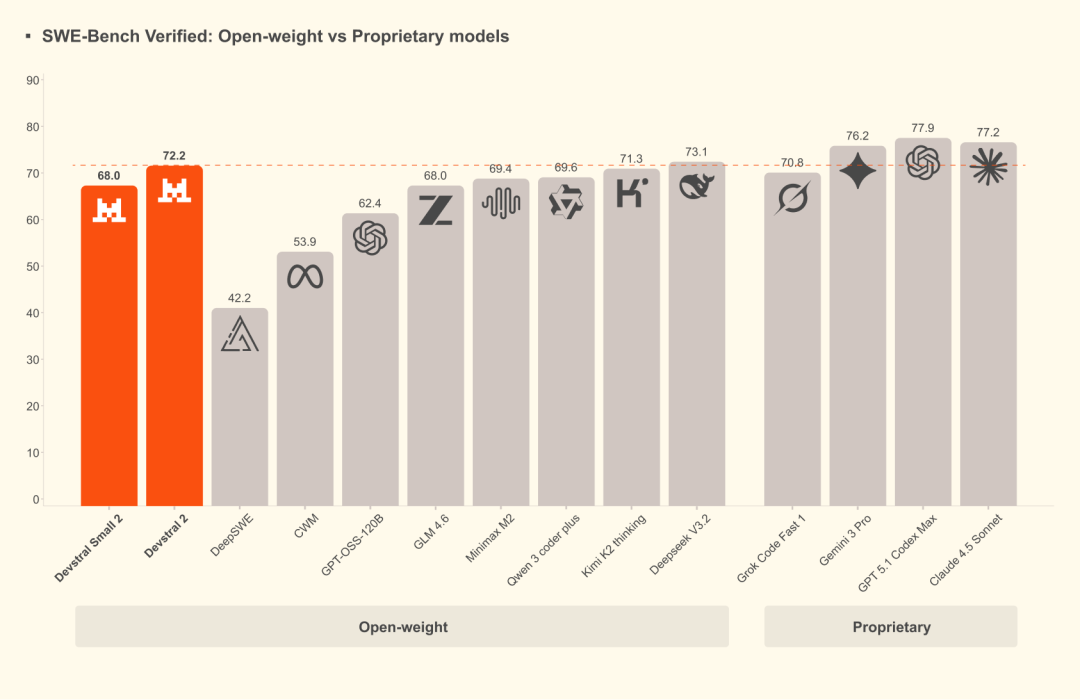
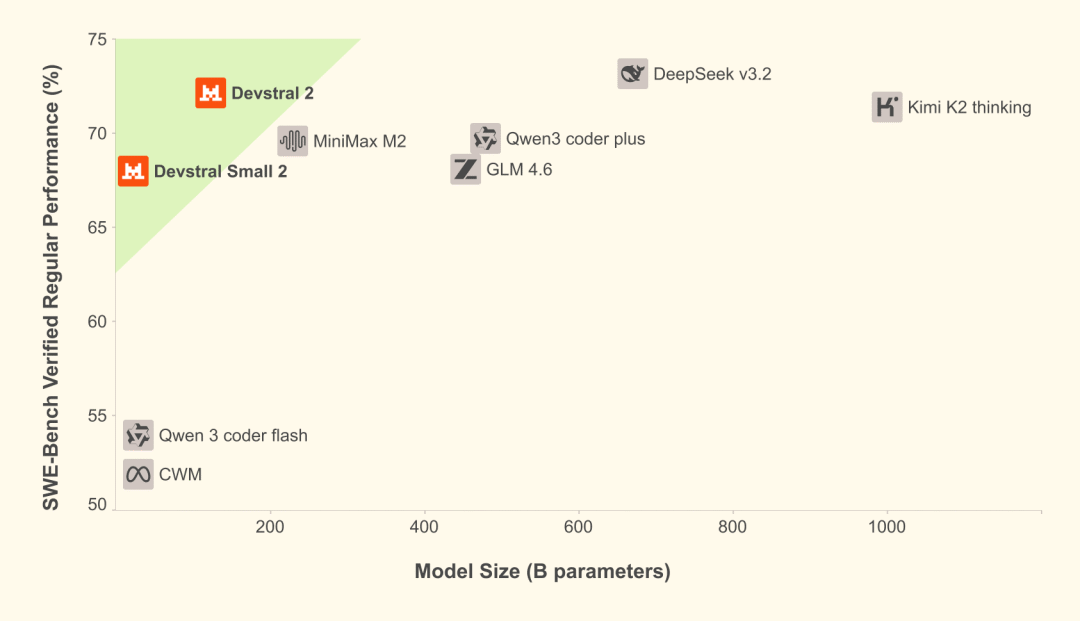
Devstral 2和Mistral Vibe CLI。Devstral 2提供两个尺寸:Devstral 2(123B)采用修改版 MIT 许可证,Devstral Small 2(24B)采用 Apache 2.0 许可证,两者均为开源模型。Devstral 2在SWE-bench Verified上取得 72.2% 的分数,而Devstral Small 2获得 68.0% 的分数。Mistral Vibe CLI是一款为Devstral构建的原生 CLI Agent,能够在终端中实现端到端的代码自动化。Devstral 2目前可通过 API 免费使用,其定价在免费期后为每百万输入/输出令牌 0.40/2.00美元,Devstral Small 2的定价为 0.10/0.30美元。Kilo Code 在 12月 内免费提供这两个模型。Devstral 2是一个拥有 1230亿 参数的密集型 Transformer 模型,支持 256K 上下文窗口,在SWE-bench Verified上达到 72.2% 的分数。Devstral Small 2拥有 24B 参数,在SWE-bench Verified上得分 68.0% 。Mistral Vibe CLI是一款由Devstral驱动的开源命令行编程助手,可在终端或通过Agent Communication Protocol集成到首选 IDE 中,使用自然语言探索、修改和执行代码库的更改。用户可以对工具执行进行编程控制、切换自动批准、通过简单的config.toml配置本地模型和提供商,并控制工具权限以匹配工作流程。Vibe CLI的源代码根据 Apache 2.0 许可证发布。https://mistral.ai/news/devstral-2-vibe-cli https://github.com/mistralai/mistral-vibe https://huggingface.co/mistralai/Devstral-2-123B-Instruct-2512 https://blog.kilo.ai/p/mistral-ai-makes-2-models-free-all
智谱发布GLM-ASR-Nano-2512语音识别模型
#2智谱 发布了开源语音识别模型
GLM-ASR-Nano-2512,该模型在保持紧凑体积的同时,性能超越OpenAI Whisper V3,并针对方言和低音量语音进行了优化。智谱 发布了开源语音识别模型
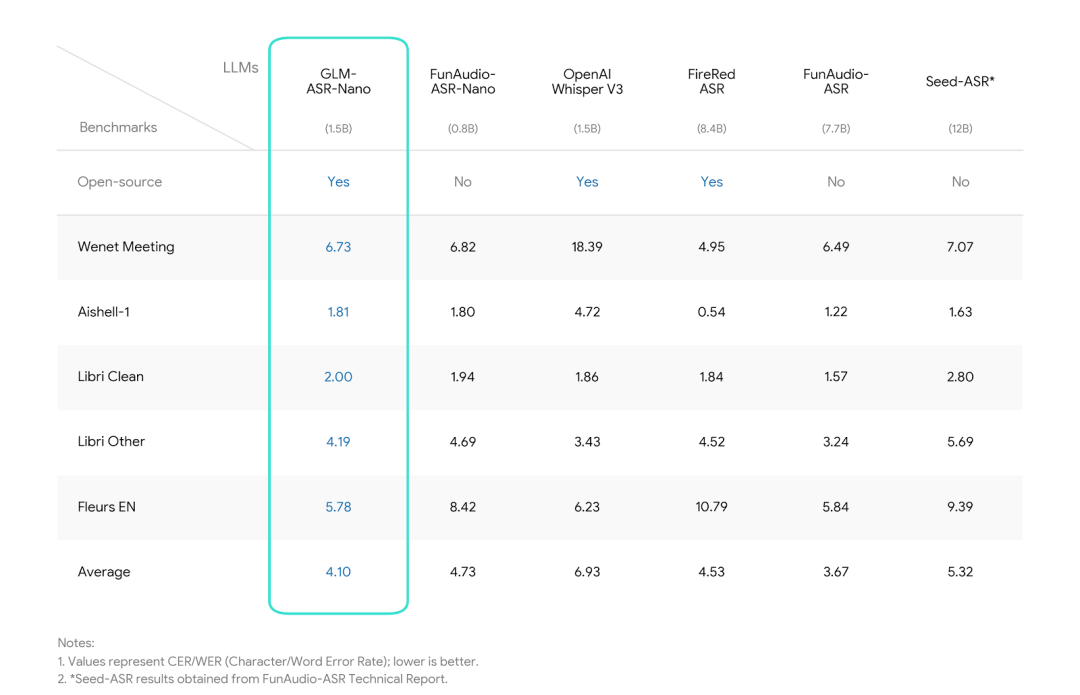
GLM-ASR-Nano-2512,该模型拥有 15亿 参数,设计用于处理现实世界的复杂场景。在保持紧凑体积的同时,它在多个基准测试中的表现优于OpenAI Whisper V3。模型的主要特点包括对标准普通话和英语之外的方言如粤语的高度优化,以及对“耳语/轻声说话”等低音量语音的专门训练和准确转录能力。https://huggingface.co/zai-org/GLM-ASR-Nano-2512 https://github.com/zai-org/GLM-ASR
智谱开源AutoGLM手机智能助理框架
#3智谱 开源了基于
AutoGLM构建的手机智能助理框架Phone Agent,具备多模态屏幕理解与自动化操作能力,旨在让 AI 学会使用手机。智谱 开源了基于
AutoGLM构建的手机智能助理框架Phone Agent,该框架具备多模态屏幕理解与自动化操作能力,旨在让 AI 学会使用手机。开源内容包含核心模型AutoGLM-Phone-9B,完整的Phone Use能力框架与工具链,覆盖 50余款 主流中文应用的可直接运行 Demo,以及针对 Android 的适配层、示例工程、文档和快速上手指南。核心模型采用 MIT 开源许可证,所有代码则以 Apache-2.0 开源许可证托管于 GitHub。该项目仅限研究与教育用途,严禁用于非法活动。https://huggingface.co/zai-org/AutoGLM-Phone-9B https://github.com/zai-org/Open-AutoGLM https://mp.weixin.qq.com/s/5p0MSgccjqOduErlaf1V4g
Linux基金会成立Agentic AI基金会
#4Linux基金会 宣布成立
Agentic AI Foundation (AAIF),这是一个旨在推动 agentic AI 透明、协作和标准化发展的中立开放基金会,获得了多家科技巨头的支持。Linux基金会 宣布成立
Agentic AI Foundation (AAIF),这是一个旨在推动 agentic AI 透明、协作和标准化发展的中立开放基金会。AAIF由 Anthropic、Block 和 OpenAI 联合创立,并得到 Google、Microsoft、AWS、Cloudflare 和 Bloomberg 等公司的支持。作为启动项目,Anthropic 捐赠了Model Context Protocol (MCP),Block 捐赠了goose,OpenAI 捐赠了AGENTS.md。AAIF的成立旨在为 agentic AI 生态系统提供一个中立的、开放的基础,确保这项关键技术能够以透明、协作的方式发展,并推动领先开源 AI 项目的采用。其创始项目AGENTS.md、goose和MCP为共享的工具、标准和社区驱动创新生态系统奠定了基础。https://aaif.io/ https://www.anthropic.com/news/donating-the-model-context-protocol-and-establishing-of-the-agentic-ai-foundation https://openai.com/index/agentic-ai-foundation/
Gemini CLI 加入候补名单可获 Gemini 3访问
#5Gemini CLI项目宣布,免费层用户仍有最后机会通过加入候补名单来获取Gemini 3的访问权限,申请将于本周五截止。Gemini CLI项目宣布,针对免费层用户提供获取Gemini 3访问权限的最后机会。该项目仍在接受用户提交候补名单申请,并计划于 本周五 关闭候补名单。届时,所有在名单上的用户都将获得访问资格。 用户可通过指定链接提交候补名单申请以获取访问权限。项目官方明确指出,本周五 是申请的最后期限。https://goo.gle/geminicli-waitlist-signup
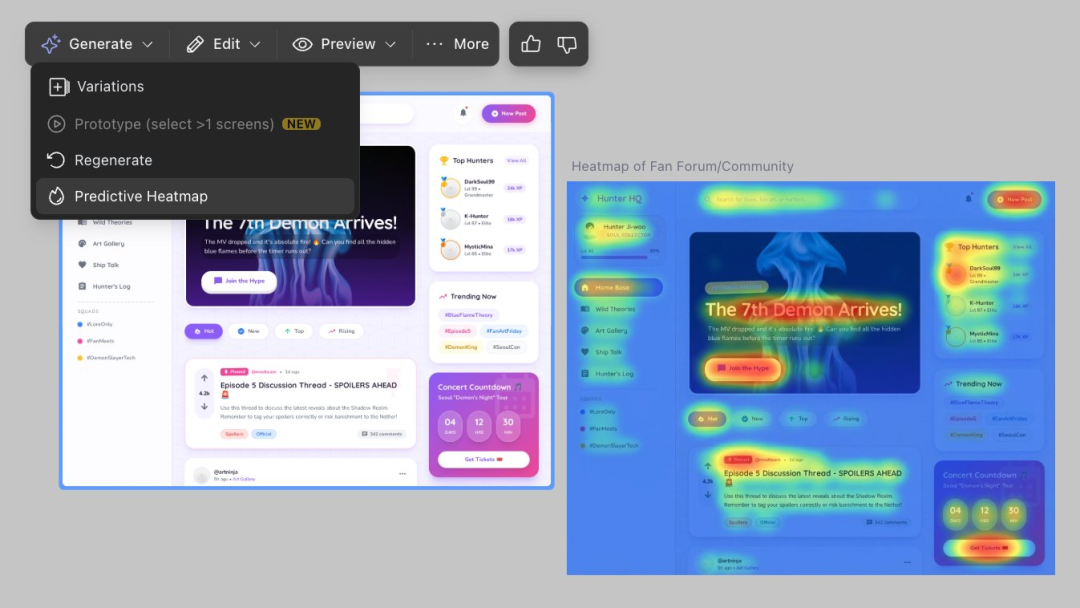
Google Stitch推出Predictive Heatmaps功能
#6Google 在其
Stitch产品中推出了Predictive Heatmaps新功能,帮助设计师在开发前通过模拟用户视觉行为来审计设计的注意力焦点。Google 在其
Stitch产品中推出了名为Predictive Heatmaps的新功能。该功能作为Shipmas Day 2的额外发布,旨在帮助设计师在开发前对任何设计的屏幕进行即时注意力审计,确保用户关注点与设计目标一致。Predictive Heatmaps通过模拟用户视觉行为,生成热力图来显示用户最可能关注的界面区域。https://x.com/stitchbygoogle/status/1998536836248121654
Augment Code发布Context Engine SDK
#7Augment Code 发布了
Context Engine SDK,允许开发者构建能够从代码库、文档和配置等来源检索信息的 Agent 和工具。Augment Code 发布了
Context Engine SDK,允许开发者构建能够从代码库、文档和配置等来源检索信息的 Agent 和工具。此前,该公司的Context Engine已作为MCP服务器向所有 Agent 开放。Context Engine SDK提供了快速入门指南和示例,Augment Code 称将在未来几周内推出更多功能。https://x.com/augmentcode/status/1998527977035100389 https://docs.augmentcode.com/context-services/sdk/overview
Qwen Code发布近期版本更新说明
#8Qwen Code 发布了从
v0.2.2至v0.3.0的重大版本更新,引入了Stream JSON支持和全面的国际化功能,并对安全性与稳定性进行了多项改进。Qwen Code 近期发布了从
v0.2.2至v0.3.0的重大版本更新,引入了Stream JSON支持和全面的国际化功能,并对安全性与稳定性进行了多项改进。更新新增了
Stream JSON支持,通过--output-format stream-json参数实现流式输出,并使用--input-format stream-json处理结构化输入。在国际化方面,
Qwen Code内置了英文和中文界面,并支持自定义语言包扩展。用户可通过/language ui zh-CN命令一键切换界面语言,或使用/language output Chinese设置 AI 的输出语言。安全性和稳定性方面,更新修复了以 20MB 缓冲区限制导致的内存耗尽风险,解决了 Windows 编码问题以避免字符乱码,并增强了对
ripgrep二进制文件的检测与跨平台兼容性。此外,认证系统进行了重构,优化了authType管理,修复了集成测试以确保 CI/CD 管道的稳定。同时,更新包含对ModelScope提供商的支持、stream_options处理、提示补全优化及终端通知增强,通过多项核心修复显著提升了整体稳定性。https://github.com/QwenLM/qwen-code
DiffSynth-Studio发布Qwen-Image-i2L模型
#9DiffSynth-Studio 发布了名为
Qwen-Image-i2L(Image to LoRA)的开源模型套件,能够将单张或多张图像输入,快速输出对应的 LoRA 模型。DiffSynth-Studio 发布了名为
Qwen-Image-i2L(Image to LoRA)的开源模型套件,该套件能够将单张或多张图像输入,输出对应的 LoRA 模型。该套件包含四个不同侧重的模型,分别是Qwen-Image-i2L-Style、Qwen-Image-i2L-Coarse、Qwen-Image-i2L-Fine和Qwen-Image-i2L-Bias,旨在支持风格迁移和内容细节的快速 LoRA 训练,并可作为 LoRA 训练的初始化权重以加速收敛。https://www.modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L/summary
Cognitive-Lab发布多语言多模态嵌入模型NetraEmbed
#10Cognitive-Lab 发布了
M3DR框架及其模型NetraEmbed与ColNetraEmbed,旨在解决多语言环境下的多模态文档检索问题,并在跨语言检索任务上取得了最先进的性能。Cognitive-Lab 发布了名为
M3DR(Multilingual Multimodal Document Retrieval)的框架及其模型NetraEmbed与ColNetraEmbed,旨在解决多语言环境下的多模态文档检索问题。该框架利用合成多语言文档数据,并通用化于不同的视觉语言架构和模型尺寸,通过对比学习训练模型,使文本和文档图像能够学习到统一的、可跨语言迁移的表示。该研究在 22种 类型多样的语言上进行了验证,并在单语、多语和混合语言设置下进行了全面评估,其模型NetraEmbed和ColNetraEmbed在跨语言检索任务上取得了最先进的性能,相对提升约 150% 。https://arxiv.org/abs/2512.03514 https://huggingface.co/Cognitive-Lab/NetraEmbed
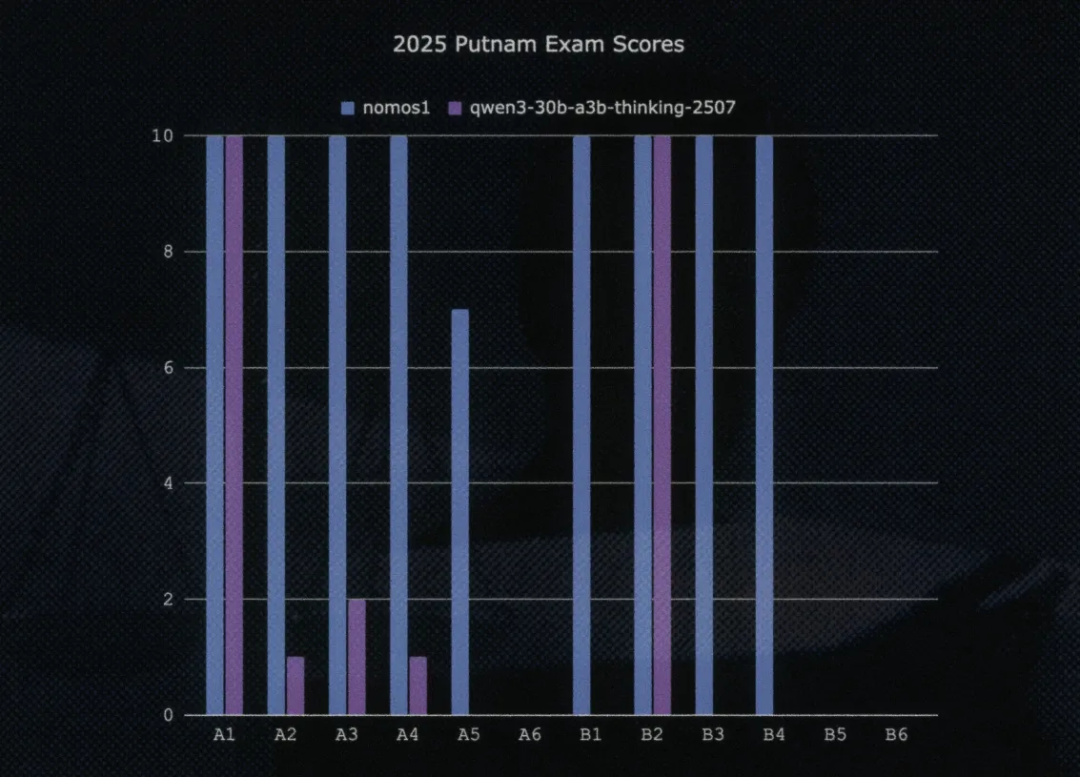
NousResearch开源Nomos-1模型
#11NousResearch 开源了专为数学问题求解和自然语言证明编写的模型
Nomos-1,该模型在Putnam 2025数学竞赛中取得了优异成绩。NousResearch 开源了专为数学问题求解和自然语言证明编写的模型
Nomos-1。该模型是Qwen/Qwen3-30B-A3B-Thinking-2507的特化版本,拥有 310亿 参数,与 Hillclimb AI 合作训练。Nomos-1需配合同源开源的Nomos Reasoning Harness使用。在Putnam 2025数学竞赛中,使用该推理框架的Nomos-1得分为 87/120,而基础模型Qwen3-30B-A3B-Thinking-2507得分仅为 24/120。此成绩在 2024年 的 3988名 参赛者中可排名第 2。https://huggingface.co/NousResearch/nomos-1 https://github.com/NousResearch/nomos
One-to-All Animation发布高效角色动画模型
#12One-to-All Animation是一个统一框架,用于高保真角色动画和图像姿态迁移,能够处理任意布局的参考图像,并提供了 14B 和 1.3B 两种参数规模的模型。One-to-All Animation是一个统一框架,用于高保真角色动画和图像姿态迁移,能够处理任意布局的参考图像,解决了现有扩散模型在空间未对齐参考-姿态对方面的限制。该项目提供了 14B 和 1.3B 两种参数规模的模型,并公开了相关论文、项目页面和 GitHub 代码库。演示内容显示,模型能够将单一参考图像适配到多种运动模式,展现出灵活的运动控制能力。14B 模型和 1.3B 模型均提供了多组参考图像与不同运动序列的生成示例,1.3B 模型还支持更长的视频及域外案例。
https://ssj9596.github.io/one-to-all-animation-project/ https://huggingface.co/MochunniaN1/One-to-All-14b https://github.com/ssj9596/One-to-All-Animation
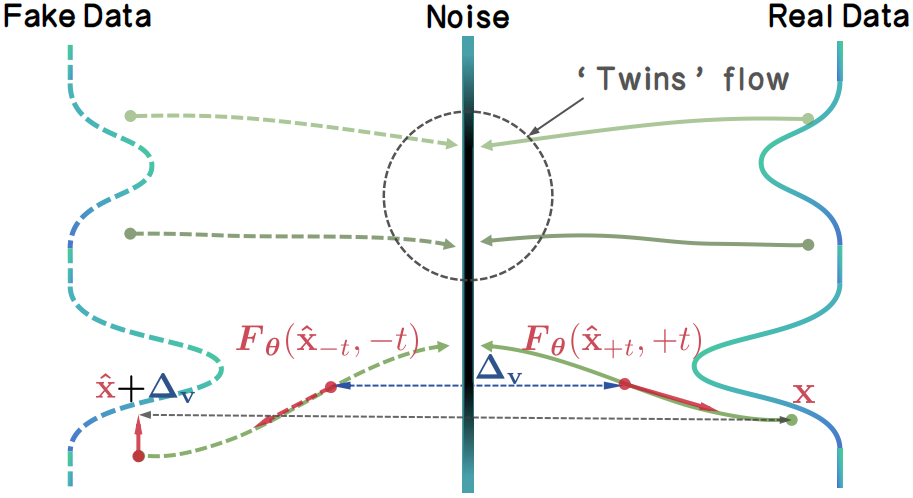
inclusionAI发布TwinFlow框架
#13inclusionAI 发布了名为
TwinFlow的新框架,该框架通过自对抗流技术实现了大型模型的高质量一步生成,无需辅助网络,易于扩展。inclusionAI 发布了一个名为
TwinFlow的新框架,该框架通过自对抗流技术实现了大型模型的高质量一步生成,无需辅助网络,易于扩展至 20B 参数规模的模型训练。TwinFlow通过扩展时间区间并利用负时间分支,在模型内部创建自对抗信号,通过最小化速度场差异来校正模型,从而将其转变为一步或少量步生成器。其关键优势在于单模型简易性,消除了对辅助网络的需求,并在大规模训练中具有良好的可扩展性。项目已发布TwinFlow-Qwen-Image-v1.0模型,并正在研发旨在提升速度的Z-Image-Turbo版。https://huggingface.co/inclusionAI/TwinFlow https://github.com/inclusionAI/TwinFlow
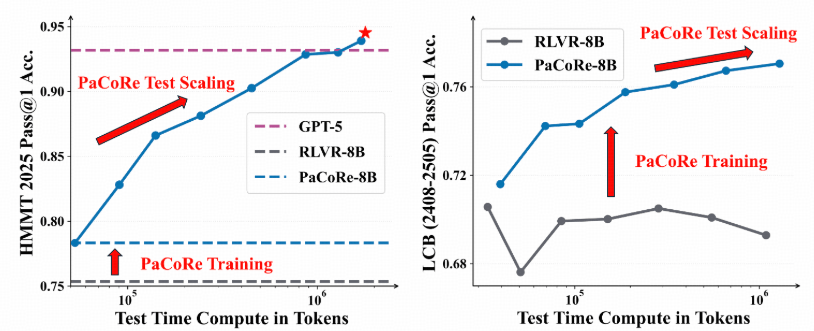
stepfun-ai开源PaCoRe推理框架
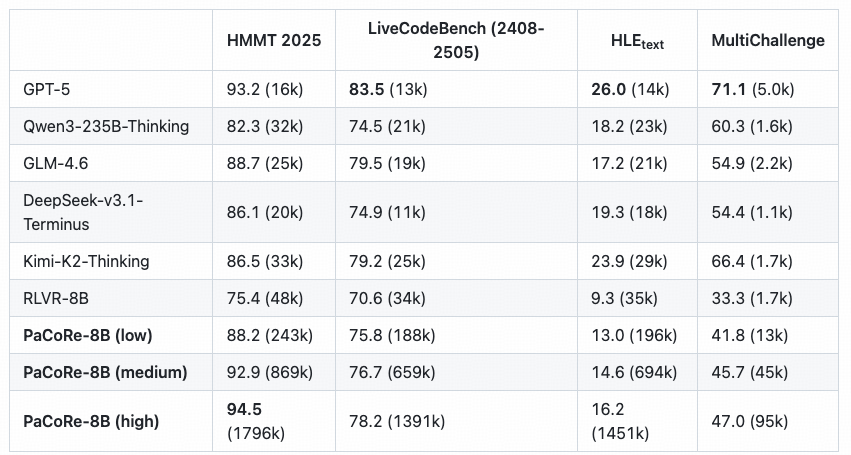
#14stepfun-ai 开源了
PaCoRe(Parallel Coordinated Reasoning),一个通过并行协同推理扩展测试时计算的框架,在数学竞赛HMMT 2025上,一个 8B 参数模型以 94.5% 的准确率超过了GPT-5的 93.2% 。stepfun-ai 开源了
PaCoRe(Parallel Coordinated Reasoning),一个通过并行协同推理扩展测试时计算的框架,包含模型、数据和推理代码。该框架通过多轮并行探索与协调,突破了上下文限制,在数学竞赛HMMT 2025上,一个 8B 参数模型以 94.5% 的准确率超过了GPT-5的 93.2% 。https://github.com/stepfun-ai/PaCoRe https://huggingface.co/stepfun-ai/PaCoRe-8B
Cerebras发布DeepSeek-V3.2压缩模型
#15Cerebras 发布了基于
DeepSeek-V3.2的两个压缩模型,通过REAP方法分别实现了 25% 和 50% 的专家剪枝,旨在降低部署成本和内存需求。Cerebras 发布了基于
DeepSeek-V3.2的两个压缩模型DeepSeek-V3.2-REAP-508B-A37B和DeepSeek-V3.2-REAP-345B-A37B,通过REAP方法分别实现了 25% 和 50% 的专家剪枝,旨在降低部署成本和内存需求,同时保持近无损性能。https://huggingface.co/cerebras/DeepSeek-V3.2-REAP-508B-A37B https://huggingface.co/cerebras/DeepSeek-V3.2-REAP-345B-A37B
Qwen团队发文介绍SAPO强化学习方法
#16Qwen团队 发文介绍一种名为
Soft Adaptive Policy Optimization(SAPO)的新型强化学习方法,旨在解决大语言模型强化学习中策略优化的不稳定问题。Qwen团队 发文介绍一种名为
Soft Adaptive Policy Optimization(SAPO)的新型强化学习方法,旨在解决大语言模型强化学习中策略优化的不稳定问题。SAPO通过平滑的温度控制门控函数替代硬剪切,在保持稳定性的同时保留更多有效学习信号,已在多个基准测试中证明了其在训练稳定性、Pass@1性能及跨任务泛化能力上的优势。https://arxiv.org/abs/2511.20347 https://qwen.ai/blog?id=sapo
OpenAI发布首批认证课程
#17OpenAI 宣布推出首批认证课程,旨在帮助人们提升 AI 技能,为未来工作做准备,目标是在 2030年 前为 1000万 美国人提供认证。
OpenAI 宣布推出首批认证课程,旨在帮助人们提升 AI 技能,为未来工作做准备。这些课程包括面向企业和公共部门合作伙伴的
AI Foundations课程,以及在 Coursera 上线的ChatGPT Foundations for Teachers课程,目标是在 2030年 前为 1000万 美国人提供认证。https://openai.com/index/openai-certificate-courses/
Google测试Veo 3.1模板功能
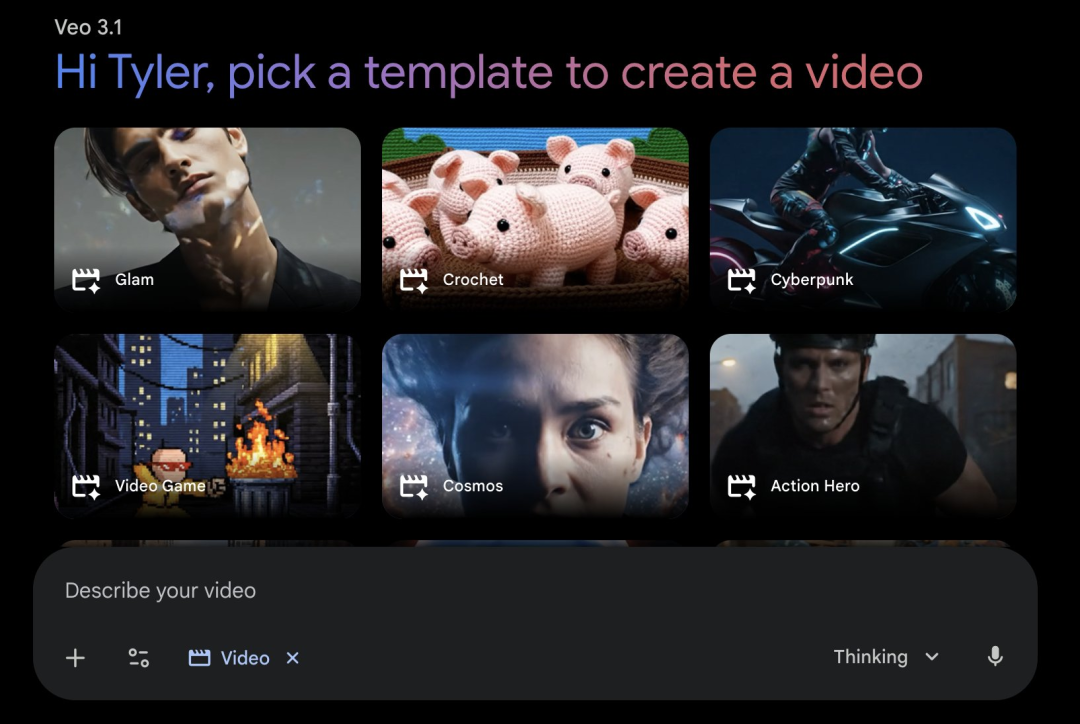
#18Google 正在
Gemini应用中为小部分用户测试一项实验性的Veo 3.1模板库功能,用户可选择预设模板或上传图片自定义以生成视频。Google 正在
Gemini应用中为小部分用户测试一项实验性的Veo 3.1模板库功能。用户可通过工具菜单中的“Create videos”选项选择并提交预设模板,或上传个人图片以自定义模板。该测试旨在收集用户反馈,以优化视频生成体验。此项功能是 Google 将前沿 AI 技术带给数亿用户努力的一部分。https://x.com/GeminiApp/status/1998465360409014677
OpenAI新图像模型疑似现身
#19代号为
Chestnut和Hazelnut的新图像模型在多个平台被发现,外界推测其属于 OpenAI,可能是下一代GPT图像模型,图像生成质量被认为很高。代号为
Chestnut和Hazelnut的新图像模型在LM Arena和Design Arena等平台被发现,这些模型被外界推测属于 OpenAI。部分讨论称其为OpenAI Image v2或下一代GPT图像模型,并开始出现其生成的图像样本。有观察者认为其图像生成质量很高。另有猜测称,该模型可能与GPT 5.2一同发布,并可能涉及对公众人物图像的生成与编辑功能以吸引新用户。https://x.com/testingcatalog/status/1998444164510281982
Meta Avocado模型延期至2026年
#20Meta 正在开发的新前沿大型语言模型
Avocado,作为Llama系列的继承者,因测试表现不佳和训练挑战,发布时间已从 2025年底 延期至 2026年第一季度,且可能转为专有模型。Meta 正在开发一款名为
Avocado的新前沿大型语言模型,作为其Llama系列模型的直接继承者。该模型原计划在 2025年底 前发布,但现已延期至 2026年第一季度,此延期主要归因于模型在测试中表现不佳以及训练过程中遇到的挑战。与Llama系列的开源策略不同,Avocado很有可能会成为专有模型,这标志着 Meta 战略从“开源一切”的转变。https://www.cnbc.com/2025/12/09/meta-avocado-ai-strategy-issues.html
阿里成立千问C端事业群
#21据报道,阿里 已成立千问 C 端事业群,由原智能信息与智能互联两个事业群合并重组而来,首要目标是将千问打造成为 AI 时代的超级 APP。
据报道,阿里 已成立千问 C 端事业群,该事业群由原智能信息与智能互联两个事业群合并重组而来,包含千问 APP、夸克、AI 硬件、UC、书旗等业务。阿里巴巴 在内部沟通中提及,千问 C 端事业群的首要目标是将千问打造成为一款超级 APP,成为 AI 时代用户的第一入口。未来,还将进一步把千问打造成无处不在的 AI 助手,覆盖眼镜、PC、汽车等场景,让每一个普通人都能随时随地使用 AI,并持续从中受益。
印度拟推AI训练版权新规
#22印度工业和内贸促进部发布一项拟议框架,要求 AI 公司为其模型训练中使用的受版权保护内容向新型集体管理机构支付版权使用费,此举旨在降低合规成本并确保创作者获得报酬。
印度工业和内贸促进部发布一项拟议框架,要求 AI 公司为其模型训练中使用的受版权保护内容向新型集体管理机构支付版权使用费,相关费用随后将分配给创作者。此举旨在降低 AI 企业合规成本,同时确保权利人获得合理报酬。该提案被视为最具干预性的举措之一,与美国和欧盟的政策辩论形成对比。此举正值全球围绕 AI 公司使用版权材料的法律争端加剧之际。此外,Microsoft 宣布承诺向印度投资 175亿美元,以支持该国 AI 基础设施、人才和主权能力建设,这是其在亚洲最大的投资。
https://www.ithome.com/0/903/757.htm
美国战争部宣布GenAi.mil军事AI平台
#23美国战争部宣布推出军事专用 AI 平台
GenAi.mil,该平台由 Google DeepMind 的Gemini模型提供支持,旨在积极部署顶尖技术以增强美军战斗力。美国战争部宣布推出军事专用 AI 平台
GenAi.mil,该平台由 Google DeepMind 的Gemini模型提供支持。战争部长表示,推出GenAi.mil是为了积极部署世界顶尖技术,以使美军战斗力比以往任何时候都更强大。https://www.war.gov/News/Releases/Release/Article/4354916/the-war-department-unleashes-ai-on-new-genaimil-platform/
欧盟委员会调查Google涉嫌反竞争行为
#24欧盟委员会已正式对 Google 展开反垄断调查,评估其是否在未经适当补偿且未提供拒绝选项的情况下,使用发布商和 YouTube 内容用于 AI 目的,从而违反欧盟竞争规则。
欧盟委员会已正式对 Google 展开反垄断调查,旨在评估其是否在未经适当补偿且未提供拒绝选项的情况下,使用网络发布商内容以及 YouTube 视频内容用于人工智能目的,从而可能违反了欧盟竞争规则。 委员会主要关注两类潜在违规行为:一是 Google 可能利用网络发布商的内容为其搜索结果页面上的生成式 AI 服务提供支持,具体指
AI Overviews和AI Mode,而未向发布商支付补偿或允许其拒绝;二是 Google 可能使用 YouTube 上传播的视频及其他内容来训练其生成式 AI 模型,同样未向创作者提供补偿或拒绝选项。调查将审视 Google 是否通过施加不公平条款或给予自身特权访问权来扭曲竞争,使其他 AI 模型开发者处于不利地位。https://ec.europa.eu/commission/presscorner/detail/en/ip_25_2964
fal完成1.4亿美元D轮融资
#25fal宣布已完成 1.4亿美元 D 轮融资,此轮融资由 Sequoia、Kleiner Perkins 和 NVIDIA 领投,新资金将用于扩展其全球平台并支持生成式媒体初创企业。fal宣布已完成 1.4亿美元 D 轮融资,此轮融资由新投资者 Sequoia、Kleiner Perkins 和 NVIDIA 领投,现有合作伙伴也继续提供支持。这笔新资金将使fal能够将其平台扩展至全球,并提供将定义生成式媒体未来的下一代能力。公司团队已扩大至 70人,正在招聘工程、产品、设计、市场和运营等职位。与此同时,fal宣布设立fal生成式媒体基金,用于支持在该领域构建下一代公司的初创企业。https://blog.fal.ai/our-series-d-scaling-fal/
提示:内容由AI辅助创作,可能存在幻觉和错误。
-